Notes from Computers in Libraries 2022
Online
Narrative
From Tuesday through Thursday I attended Computers in Libraries 2022, virtually. This conference allowed me to present on co-authored research about how Primo has been used in the CSU Libraries. We had previously presented our findings internally to the ULMS Discovery Functional Committee where it was well-received and we used feedback from that to improve our presentation for the national stage. Since almost everything in libraries now has something to do with ‘computers’ the content at CIL 2022 was varied and I sampled from the various content tracks that were organized based on professional interests and job responsibilities. Below are first the session descriptions and then my session notes, which are of varying length and intelligibility depending upon how informative I found each session.
Tuesday March 29th
Keynote: Libraries, Climate & the Crowd: A New Concept of Digitality
Michael Peter Edson, Digital Strategist, Writer, Independent Consultant
How should your library respond to the climate emergency and natural disasters? Where does librarianship end and citizenship begin? And what digital tools and mindsets can libraries use to help create a society that is joyous, sustainable, and just? In this provocative and inspiring keynote, digital pioneer and former Smithsonian tech leader Edson argues that the library sector is operating with an outdated concept of digitality that is unable to answer today’s most important questions about technology, society, and change. An updated concept of what “digital” means in the 2020s — new tools, new skills, and a new understanding of the digital public sphere — can provide a new direction for digital librarianship and unlock new capabilities within the sector and in the communities we serve. Be challenged by this popular speaker with new ideas to be even more innovative, creative, and community focused in your organization and environment!
Our understanding of digitality is outdated. This is wild time to be alive and libraries and cultural institutions have a responsibility to the public. Digital infrastructure requires a significant expenditure of resources and affects the climate.
‘The big fricking wall’. A concept from NAME. On one side is where we are, we plant gardens and make it nice; but on the other side is where we need to be: solving large societal problems.
Technological foundations allow for further acceleration of technological development. We need to think about climate change. Winning the battle against climate change slowly is functionally the same as losing.
If you/we are keeping our powder dry to fight climate change and against political catastrophe then you are missing the opportunity. The time is now.
An EU initiative is promising but Edson does not feel it leverages digitality sufficiently. People often find themselves on the comfortable side of the ‘big fricking wall’. How can cultural institutions get over or under the wall? At a workshop of cultural/library workers they discussed digitality and he realized that many people were focused on the dark side of the technology. We are missing an opportunity to move on climate using digital technology.
The aspects of digitality that could work to fight against climate change are areas that are not our strengths in the cultural institutions: working at speed, conservative-sustaining mindset, lack of history in ‘selling’ ideas to ‘customers’, and lack of clarity about the threat of climate change.
What happened after Trump pulled out of the Paris Climate Accords? He went around to cultural institutions websites after this act and noticed that no one was highlighting it. These institutions are government funded but we have a lot of leeway to speak. Workers in these places spoke out on social media and made statements but the institutional voices were absent.
The Pew Research Foundation reports on the internet and how connectivity is changing the world are a great resource. They show both the light and dark side of connectivity. On the positive empowering side, a consistent aspect of digitality is that people report it to be important in finding more information that is useful for their lives.
- digital culture is inseparable from ‘normal’ civic life
- the gains of digitality are still there; people are just focusing on the dark side now
- basic Web 2.0 elements still hold true and can be applied to cultural institutions
- most of digital’s force lies in the open areas and aspects of the web “the dark matter”, not on our protected cultural walled gardens
- the ‘big fricking wall’ is made of: fear. We have hugged the idea of openness and crowd scaling on the web so tightly that it can’t move freely.
- think big, start small, move fast - these remain an excellent recipe and we must use it to generate awareness around climate change
Lessons Learned From the Brands You Love
Alyx Park & Meg Slingerland
Why is your library’s website brand so important? Your website lets the world know what to expect of your library’s services and programs. It helps communicate everything your library has to offer and emphasizes that your library is much more than a place patrons use to borrow collections. We have moved into a new era of marketing—one where the creation of value through content-driven experiences is the focus. Today, content is king. This session takes a deep dive into corporate brands which are changing the game and explores how you can apply the lessons learned to your library’s marketing strategy. Learn how to be agile enough to quickly adapt to the ever-changing web trends and take the best practices of the web from other industries and apply them to your library!
Central Rappahannock Regional Library serves several communities including Fredericksberg VA. The website staff are part of the larger PR/marketing division in the library.
2022 Marketing Trends source: Adobe 2022 Marketing Trends
- Pandemic prompted companies to focus on customer experience, need to think about customer holistically
- Customers expect a personalized/customizable experience
- “integrated marketing platforms” have reduced total cost of ownership by 30% in numerous case studies
- Marketing and IT must work together to achieve overall goals of parent organization
Fixer Upper brand
Lessons:
content is king
find your style, refine it
identify a niche, make customers feel at home with your business
rethinking “place” as a character
highlighting the community resonates with the community
marketing is about more than buying things
CRRL does ‘Guest Picks’ where community members share their favorite books. Pick community leaders and families that use the library frequently. Guests suggest 5 to 10 items held in the catalog and their picks are put up on the website along with a brief biography. The feature is on an invitation-only basis.
Whole Foods brand
Lessons:
design with local flair
location-based marketing goes beyond differentiation (Whole Foods uses geofenced ads when people are grocery shopping at their competitors)
focus on self-service
strong location-based tools helps on multiple levels
CRRL has 10 branches (and a makerspace location) and associates to a users selected branch when authenticated. Every branch has its own library location webpage. Each page has detailed information about the amenities offered at the branch. Users can browse through new arrivals at that particular branch.
Disneyland brand
Lessons:
use landmarks to keep moving and direct traffic
Color creates a worthwhile customer journey
- use color to evoke emotions
- use color to create depth
- use color to distract (go-away green and blending blue)
CRRL has 3 distinct colors in their branding. On long pages they use all 3 to differentiate important areas of interest. Gradients are used within the palate to make certain areas pop out.
Q&A:
Q. What CMS do they use?
A. Wordpress
Keeping Search Configuration Options Open
w/ Heather L. Cribbs
Modern discovery layers allow for a wide variety of design configurations. One essential consideration when creating a search environment is the complexity of search options available to the end user. This multi-campus study took a big data approach and examined 4 years of data collected from the California State University (CSU) libraries and compared user search query behavior across all libraries. There is a lot of research that suggests reducing cognitive overload results in a better user experience. Understanding how users search is key to designing a library which is more accessible to all. When configuring your library catalog, certain questions must be answered, such as whether to cater to advanced librarian query behavior or adopt a simpler, commercial-style approach. Designing for all users involves considering a diverse userbase with a wide range of abilities, keeping edge cases in mind, and building from proven web design principles. Get tips and learnings from this talk.
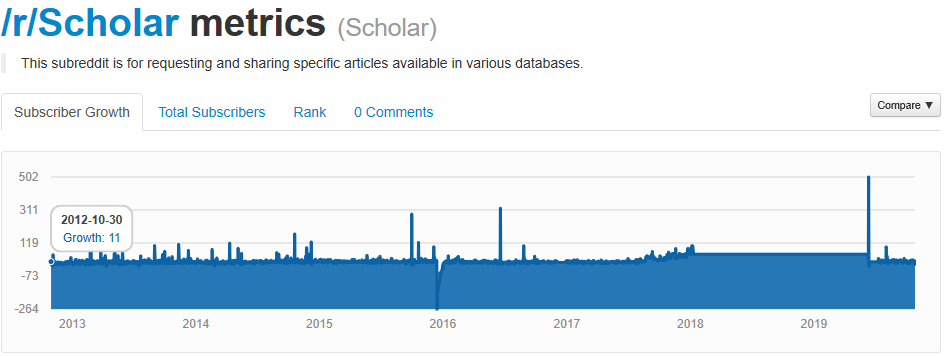
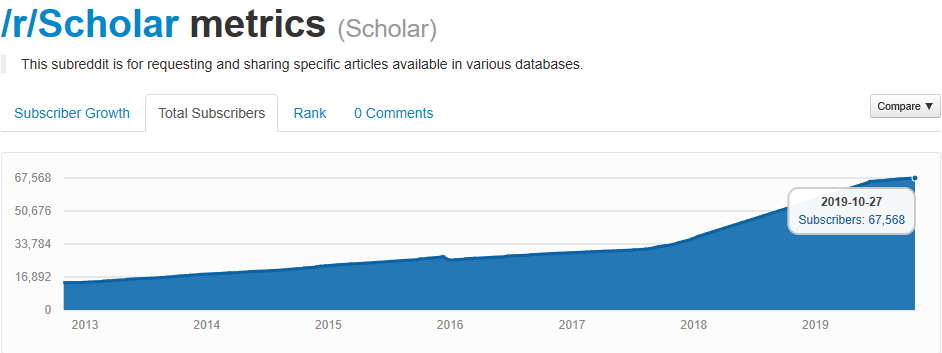
My co-presented session. 126 attendees.
Chat Box: Small Change, Big Difference
Colleen Quinn, John DeLooper, Michelle Ehrenpreis, Ryan Shepard
Our first presentation provides learnings from our speakers’ experience implementing a chatbot developed by Ivy.ai on its website. Discover what a chatbot is, how chatbots work, and how the library and IT department worked together to prepare for the bot’s implementation and hone the chatbot’s search algorithms. Learn how they leveraged the chatbot to improve its website for better user experience and better findability for all users, with a focus on improvements related to patrons asking questions via the chatbot. In addition, leave with some lessons learned from the implementation process and future plans for assessing the chatbot’s use and effectiveness so your implementation of a chatbot will also be successful. The second presentation features how a floating chat box was added to all the library pages. With a student body of approximately 90,000 global, asynchronous learners, librarians typically answer 12,000-15,000 questions per year via email, phone, zoom, and chat. Questions increased substantially within minutes of adding the box. The first week, the library saw a 25% increase in the number of questions. Along with the implementation of the floating chat box, other changes were made to the website, Hear how this strategy has changed library statistics and staffing models, get tips to help you navigate the waters of adding a floating chatbox, and understand how staffing and service changes can impact customer satisfaction.
University of Maryland Global Campus.
UMGC rolled out Springshare’s proactive chat, floating option. There were some web accessibility problems with the floating widget so they left static embedded widgets in many places.
They saw an 83% increase in chats comparing Fall 2020 to 2021. 70% of their chat traffic was coming from the proactive widget, despite presence of other widgets in different places. They had to double up their staffing in many shifts to accommodate the increase in traffic.
They went through many iterations of adjusting the timer: 25, 20, then 15 seconds. They now have a 60 second delay when the widget is placed in EBSCO databases.
Despite the double staffing for busy shifts, there still is a struggle to deal with the traffic. They have a SOS model where they ask others to login and help. They also recognize that there will be missed chats, they put these into the LibAnswers queue.
Canned messages help a great deal.
They noticed a big decline in LibAnswers FAQ “knowledge base” traffic after introduction of proactive chat. Chat is where people are going instead of using the FAQs.
Lehman College CUNY.
Chatbots are AI using natural language that allow users to converse with the AI for various reasons.
At Lehman they are using Ivy Chatbot. Ivy runs of of web pages that are crawled and used to form a knowledge base for the chatbot. The AI forms ‘intents’ based on the crawled content.
Ivy has a human intervention feature, Inbox Zero. When it cannot answer a question it goes to a human. The librarian can intervene and the AI then learns the correct answer.
This has been a big success, seemingly. By reviewing interactions with users and Ivy, they realized aspects of their website that needed to be redesigned in light of what the chatbot was sending people. This ended up with better UX for everyone.
Their license limits them to 5 pages that will be crawled by the AI to form answers. They have to be very judicious about what pages are pointed to and what content is there.
The IT department has handled most of the implementation, otherwise it would have been unmanageable.
Q&A
Q. Have they seen this impacting the reference transactions?
A. They make it clear in the initial interaction that it is a computer and not a librarian and then give a link to how to contact librarians. Have not seen a decline in reference transactions.
Q. How many chatbots did they look at before picking Ivy?
A. Zero, the campus IT picked it.
Search Innovation Sandbox
Greg Notess
Our popular web search expert shares the latest search innovations and speculates where search of the future is headed.
Reviewed various developments and changes in Google interface and behavior. Reviewed alternatives such as Neeva.
Alternatives to 3rd party cookies
- FLEDGE
- FLoC
- Topics API to replace FLoC
Discussed various regulatory and intra-business developments such as Google payment to Apple to keep Google as default search on iOS.
Web3, unclear how this will impact commercial search engine market. Many NFT search engines are being developed. Some firms are attempting decentralized knowledge graphs. Web3 might bring to fruition the promises of Semantic Web.
Online Learning Modules & ACRL Framework
Anthony Paganelli
Paganelli discusses how online learning modules were created for university experience students to support their learning outcomes to provide quality library information instruction. The modules were designed to introduce library and information service to first-year students based on the Academic College & Research Libraries’ (ACRL) information literacy framework. The five modules that students were able to complete online served two purposes. First, the modules were embedded in a course management system that was self-graded and included in the course’s overall grade in accordance with the faculty’s request. This allowed the faculty to provide students with library information without extra work or time. Secondly, students completed the modules prior to an in-person instruction workshop, which introduces the information and terminology regarding library services and resources. With prior knowledge of the content, students are familiar and have a stronger opportunity to retain the information. Paganelli demonstrates the importance the online library learning modules have had on reinforcing library and information literacy.
WKU has a ‘university experience’ course. Not offered to all students but those in need, based on ACT/SAT scores and Kentucky state standards for college readiness. Library has designed a module embedded in the LMS.
Modules in the LMS are replacing ‘library assignments’ at the university. Faculty bought into modules because they were self-graded.
They cover each of the frames in the ACRL Framework over the semester. Each subsection of the module, centered around a frame, has content for review, a discussion, and a quiz. Quizzes are limited to 2 attempts and students can use the higher score.
They did a case study where they then brought in students who took the modules for in-person library instruction. They retook certain questions from the quizzes in person. The results were not promising and students uniformly scored below the averages in the modules. Not clear why this was the case? Working hypothesis is that students gamed the quizzes online and took the higher score rather than actually retaining any of the information from the content portion of the modules.
Getting data out of the LMS, Blackboard, they found a challenge.
In the future they will be using a pre-test knowledge check so that they can establish a baseline from which to measure the changes in knowledge.
Wednesday March 30th
Nicol Turner Lee
More than one-half of the world’s 7.7 billion people still do not have access to the Internet, including millions of people in the United States, which has led the digital revolution. Most of these non-adopters—whether by choice or circumstance—are poor, less educated, people of color, older, or living in rural communities. As the digital revolution is quickly carving out this other America, it’s likely that these people on the margins of the information-based economy will fall deeper into abject poverty and social and physical isolation.
Based on fieldwork across the United States, Turner-Lee explores the consequences of digital exclusion through the real-life narratives of individuals, communities, and businesses that lack sufficient online access. The inability of these segments of society to exploit the opportunities provided by the Internet is rapidly creating a new type of underclass: the people on the wrong side of a digital divide. Turner-Lee offers fresh ideas for providing equitable access to existing and emerging technologies. Her ideas potentially can offset the unintended outcomes of increasing automation, the use of big data, and the burgeoning app economy. In the end, she makes the case that remedying digital disparities is in the best interest of U.S. competitiveness in the technology-driven world of today and tomorrow. Learn about real-life consequences of the digital divide, and what can be done to close it.
The COVID-19 pandemic laid the digital divide bare. It is absolutely undeniable now.
ALA reported that many public libraries were cutting staff during the pandemic but that was not an indication of less demand for library services but rather a mismatch between the workforce designed for physically open facilities and the surge in demand for digital access and content.
Homework Gap - mentioned, look that up.
https://www.nsba.org/Advocacy/Federal-Legislative-Priorities/Homework-Gap
At Brookings they are now thinking of libraries as part of infrastructure. Libraries lead the way in getting people online or with hotspots ahead of schools in many parts of the country. Libraries are part of the public square and government tools that keep society going.
Her book is Digitally Invisible: How the Internet is Creating the New Underclass (forthcoming 2022, Brookings Press)
Broadband is just as much part of essential infrastructure as rural telephone lines and rural electrification. Like Roosevelt passed the Rural Electrification Act in 1936, the digital divide revealed in COVID-19 a need for a urban and rural broadband act of similar scope.
We, libraries, can’t close the divide if we also perpetuate it. We need more digital sharing of resources. We need better communication and instruction around misinformation.
- we must bring resources directly to patrons, no library can be offline
- we, as a country, must prioritize libraries as digital infrastructure
- we need more funding and cannot let the politicians off the hook
- we need to reimagine our individual roles in this ecosystem, the digital train left the station, librarians must adapt
Impact of Industry Consolidation
Marshall Breeding
The library technology industry has become highly consolidated via ongoing rounds of mergers and acquisitions. The last 2 years have seen some of the most aggressive changes. A smaller number of companies are now responsible for the strategic technology produced upon which libraries depend. Breeding discusses the impact that consolidation has had on the number and types of products available to libraries. He draws on data collected from a variety of sources to help answer these questions.
Quite a bit of consolidation in the LIS software and content industries recently.
May will see Marshall Breeding’s next Library Technology Industry Report in American Libraries magazine.
Virtually all of the change in the business landscape during past 2 years has been consolidation. The one exception was OCLC selling QuestionPoint to Springshare.
Libraries hold on to software systems for decades, typically. Big ‘lock in’ effects and/or lack of staff flexibility (or will or funding) in libraries for quick software pivots.
Major 2021 events
- FTC reviewed ProQuest’s acquisition of Innovative. (Approved)
- FOLIO moved into production grade
- Alma/Primo grew dramatically in the academic library market
Major 2022 events
- Clarivate purchased ProQuest (incl. Innovative and Ex Libris)
- Innovative continues to offer Vega for discovery
- Axiell purchased Infor
- Follett breakup, family ownership. Selling off many assets, most to private equity firms.
There is vertical and horizontal consolidation; important to differentiate between the two. Despite this, the distinct products they offer seem to continue to live. A question: does consolidation prolong the life of struggling software platforms? They now have more resources with which to develop sometimes stagnant products.
Vertical consolidation raises many questions about content/software distinctions and favoritism or preferential product treatment.
The fact that many important supplier companies are publicly traded in relatively new. Hard to say how that will affect things.
- Clarivate
- Constellation Software, Inc.
He notes that there isn’t a single issue of his Technology Industry Report that hasn’t had some consolidation, this is a long going trend.
Worrisome charts showing Clarivate (nee ProQuest) dominance in academic library software market ~65% depending on small- mid- large- sized academic libraries. But Clarivate is clearly not a monopoly.
Adoption of Alma has been “meteoric”, unprecedented adoption compared with his historical data on library ILSs.
Mining Library Data for Decision Making & Pivoting in a Pandemic
Diana Plunkett, Garrett Mason, Kasia Kowalska, Sarah Rankin
A panel of library data folks discusses how data was used to pivot during the pandemic. Each library has a different approach and discusses changing what and how they reported, using the data to determine where services were needed, what they measured and how they took action as a result (including how both staff and patron needs were measured), what they learned, and more.
Indianapolis Public Library has been reviewing statistics on the effects that COVID-19 had on their services (closures - partial/full, and cleanings). Their board also wanted information on testing rates of staff to know how pandemic was affecting employees.
They put together dashboards of service statistics (gate counts, reference question volume, circulation, public computer usage rates, etc.) that were then made available to their board.
To determine staffing needs, they were short-staffed given medical leaves, they analyzed gate counts to change operational hours just to peak times and minimize effects of partial/full closures.
Brooklyn Public Library used the Zip code data from NYC Health Dept. to guide their reopening. At certain threshold in Zip code they brought in grab-and-go and at lower rate they fully reopened (with exception of children’s activities which are on hold because of no under 5 vaccine).
There were walk-throughs where people role-played how things were supposed to work under COVID-19 protocols. They also moved checkout machines at various locations and shared this information widely. After each phase of re-opening, they did a rose/bud/thorn evaluation on how it went: what worked, what didn’t work, and what has potential. These evaluations generated a lot of free-text which was analyzed and shared.
Their BklynSTAT dashboard shows declines in almost all metrics per open hour; just the things that are possible by website are unaffected by behavior changes introduced by the pandemic.
NYPL tracked the composition of their borrowers (print only, ebook only, print and ebook ; combined with burroughs/geography). The pandemic changed their borrower composition, they had many new cards issued, lost some print only borrowers. Ebook usage surged. Physical checkouts were available but grab-and-go; the print only borrowers who dropped off apparently did not find that to meed their needs.
There was a +50% decrease in borrowers living in median household by zip code areas of 0-35k.
Higher income areas had higher ebook usage rates before pandemic and this pattern continued after. This was also true for holds usage.
Clear example of digital divide.
The usage patterns across income areas got them to re-evaluate their floating collections data. Float-driven collection change is/was resulting in lower-income areas having depleting collections while higher-income areas were having growing/pooling collections. Because of this data analysis, they have turned floating off for at least 1 year. They are in the process of re-evaluating their floating collection rules in light of equity concerns.
Checkouts per-capita for children’s books spiked in higher income areas during pandemic. Basically wealthier patrons familiar with ebooks got lots of ebooks for their children while lower income patrons did not explore ebook usage and were reliant on grab-and-go to get children’s books.
Q&A
Q. What software do you use for your dashboards?
A. INDYPL, Excel; Brooklyn, Tableau; NYPL Google Sheets, Illustrator, ggplot
The Future of Authentication: Landscape & Challenges
Jason Griffey
Access to online resources is a lot more complex than it used to be, with IP-based access starting give way to federated authentication. Changing expectations about data privacy are leading to greater scrutiny of authentication and authorization data, and the evolving regulatory landscape is increasing responsibilities for those collecting personally identifiable information. Griffey looks at the existing landscape of federated authentication and its associated technologies such as seamless access, as well as upcoming challenges to authentication and authorization in general.
Authentication: individual (username/password, ORCiD) and organizational (IP address, referrer URLs passcodes) and overlapping (username/password from your org, federated access)
Every method has trade-offs.
Web browser vendors are expected to make many changes soon/now that will affect almost all the authentication mechanisms. There is a coming authentication apocalypse. This is a result of browser developing firms trying to reduce the amount of tracking that happens across the web.
WebKit & Blink. These are really only the 2 browser engines with any uptake in the market. (Also Gecko.)
All iOS browsers are built on WebKit (even Chrome). On Windows/Linux Chrome and Edge are on Blink.
Federated authentication, even IP authentication at times, uses the same underlying features in the browser that ad-tracking cookies and scripts do. It looks the same to the browser developers as 3rd party tracking.
Because of the crackdown on 3rd party cookies, we’re seeing a rise in ‘bounce tracking’ (aka redirect tracking) where Website A sends you to Website B incredibly quickly and then back to Website A. At Website B a 1st party cookie can be set.
Authentication that uses SAML will work for the next couple years. But because of the ongoing work at browser vendors cracking down on 3rd party cookies, SAML federated access will eventually break unless it adjusted.
SeamlessAccess anticipates it will break under certain circumstances until sufficient new development happens.
What will break if 3rd party cookies are totally gone?
- SAML, depending on implementation
- IdP
To test, use Safari which will emulate the worst case scenario as far as death of 3rd party cookies.
Apple’s iCloud Privacy Relay (subscription product) breaks IP authentication.
What can we do to prepare?
- just realize that this is a problem, some things are beginning to break now, if you are troubleshooting
- anyone involved with tech support needs to educate themselves
- evaluate your access methods and gameplan out how changes will affect the user experience
- over then next 5 years we can all expect changes for basically every authentication method
- learning how to troubleshoot these new problems will be very difficult (will depend on Blink/WebKit/Gecko and combined with authentication mechanism and local configuration)
Internally we need to advocate for privacy in what data is being shared through an authentication mechanism and authentication work/methods also affect contracts for electronic resources. Externally we need to pay attention to groups that are monitoring this. No library will solve this themselves.
Q&A
Q. Will this break EZproxy?
A. It seems so, there are a couple “vulnerabilities” with how EZproxy works that will be affected by losing 3rd party cookies.
- Proxy URL (initial pickup during login) relies on referral URL
Q. Should we just force everyone onto VPN?
A. Probably not, just from a PR and level of difficulty.
Q. Is anything NOT going to break?
A. Username/password will still work. But that is not privacy-protecting.
Demystifying Copyright to Generation Z
Maria Markovic, Marko Perovic
Publishers are in perpetual competition mode to outperform each other’s platform functionalities. With Generation Z fast approaching the workforce, the glaring challenge of explaining copyright guidelines to born-digital employees becomes more apparent. Examine the future outlook and expectations for the librarians in the roles of copyright advisors, educators, and influencers: how do new technologies impact librarians’ role in the education of generation Z employees, how to develop efficient copyright education programs that demystify copyright guidelines and direct generations of restriction-free content users into the copyright compliant content use mode.
Common information pathways used for research:
- commercial public web search, e.g. Google
- PubMed
- a library
Risks:
- accuracy
- validity of access
The librarian’s constant dilemma: to be or not to be the copyright cop
Gen Z, entering the workforce. Digital natives. She ran a survey of 20-27 year olds; only 22 sample size.
Results: 100% said they repost/reshare/forward content. Free text answers indicate that respondents were familiar with Copyright as a concept. One question on survey was “What would be the best way to alert users of copyright content?” Most popular answer was some kind of intrusive pop-up message.
Gen Z (small sample) does appear to know about copyright protection for consumed content but not in detail or for their own work. Awareness of ownership with knowledge of revenue potential as well as why school/library subscribed databases were no longer free after they graduated.
Examples that educators should use are ones that will resonate.
There appears to be a dislike of fee-based content. Will this affect Gen Z behavior when they research out in the workforce or their daily lives?
David Lee King
In the last few years, there have been quite a few library engagement platforms that have appeared. Each of them does slightly different things, all with the goal of connecting with and engaging your library patrons. King gives an overview of library engagement platforms and shares the different ways these tools help to connect library patrons to the library.
Public libraries are using a variety of software to generate and sustain online and in-person engagement.
These might take place on social media, via email, or other website.
Does direct marketing email work? Research shows there is about a 28% open-rate on marketing emails, with certain sectors getting more opens and reads that others. If you think about the library as a business, there is a clear case for direct “marketing” of library services and events via email.
Gave overview of many reasons why libraries might use targeted emails.
Customer Management System, widely used in the private sector. Wide applicability to libraries.
E.g. LibConnect from Springshare, Vega from Innovative. These are for all sorts of use cases. LibCal for booking all sorts of things.
A dedicated ‘app’ for library website can help with library engagement. Others: Libby, OverDrive, Hoopla, etc. Things that the library subscribes to should work through the vendor’s mobile apps; testing required.
Examples: OrangeBoy
More about this topic in the author’s ALA Library Technology Report Library Engagement Platforms
Keynote: Opportunities for the Future
Lee Rainie, Pew Research Center
Based on Pew research, our popular and fun speaker shares results and insights for libraries looking at maintaining their strong community relevance in an uncertain and highly digital world.
Pew dropped their plans to ask questions about COVID-19 and pandemic things.
Very interesting findings about usage of technology in the pandemic as well as the effects on people. (Rather depressing.)
Thursday March 31st
Keynote: Building Intelligent Communities & Smarter Cities
Rick Huijbregts
Throughout his whole career our speaker has been interested in understanding, building, and improving the DNA of intelligent communities. From Cisco Systems working with many communities including the Toronto Public Library, to George Brown College, an intelligent community itself with 90,000 learners, 4,000 colleagues, and an eco-system of 10,000’s of partners/employers across three campuses and more than twenty buildings, to Stantec where he recently joined as Global Head of Smart Cities. Communities (big and small) are complex ‘networks’ of systems, services, and infrastructure. With the emergence of the “digital economy”, these communities are looking for solutions to optimize, enhance, and transform the experiences throughout the complex network. Today, our citizens, consumers, and community stakeholders increasingly expect - and demand - new experiences and services that are unique, differentiated, connected, and personalized. Our communities, and the next “smart cities” thrive at the intersection of people (and culture), processes (and workload), places (both virtual and in the physical world), exponential technologies (including, but not limited to, connectivity, IoT, and Artificial Intelligence), and governance. Be sparked with insights and ideas as our speaker shares tips for building future communities and launching exciting new places that straddle physical and virtual worlds.
A lot to learn from indigenous communities and an inclusive eye, at least for smart city design.
Trains during 1st industrial revolution were the first technology to dramatically reshape cities. Factories with assembly lines were the second. We are living through another revolution in how computers can/will reshape cities.
Internet of Things and metaverse will allow libraries and cities to offer services they currently don’t.
Every company is now a digital company to some degree. And every government must have some digital services.
The trains and factories and roads for cars required a lot of physical infrastructure. The transformation of cities using computers will require new physical infrastructure as well to allow connected IoT cities.
New regulation is also required, many people have already been victim of digital crimes (e.g. identity theft).
There are so many concerns implicated in smart cities (climate change, sustainable development, population growth/change, business/economic development, digital divide) that the process of development must be collaborative.
Libraries must involve themselves in their cities ‘smart city’ plans. Many cities around the world are currently having these discussions.
Natasa Hogue, Tammy Ivins
“Go to the library website” is a common phrase in classrooms and curricula across the country, reflecting the siloed nature of library resources. There often remains a fundamental barrier between the users and the library experience. Maximizing that user experience requires easing access to library resources. One way to do so is to integrate the library closely into an institution’s learning management system (LMS) through a learning tools interoperability (LTI) feature. This presentation discusses the value of using LTI to integrate library resources directly into an institution’s curricula and LMS, as well as the communication and collaboration approaches that librarians must utilize to encourage teaching faculty participation in that integration. When this process is successful, it not only eases user access to library resources, but also supports the use of the library resources as textbook alternatives in the classroom. Therefore, by leveraging LTI to integrate the library into an LMS, we can not only maximize the user experience but also maximize the library’s value to its institution.
Removing barriers between the library content and user. SSO and LTI both work. WIthout SSO (true, cross site) and LIT, many abandonment points are possible between student need for content and access to it.
LTI integration LIRNProxy is the only certified LTI compliant proxy. https://www.lirn.net/products-and-services/lirn-services/lirn-proxy/
When SSO is activated, the vendor <embed> features will work to display content within the LMS. Otherwise, proxied, stable URLs are second-best alternative. But these are not always clear for faculty to find.
Low-stakes assignments work to build familiarity with the library. Good to get some of them in before students have high-stakes papers.
Enhancing Library Technology Competencies: Continuous Learning Program
Jennifer Browning
Through her development of a unique multi-step continuous learning program at Carleton, LSP Team Experts, Browning has been working with library staff to inspire continuous learning philosophies to improve confidence and expertise in their use of library technologies. She highlights the strategies taken to develop and support a local continuous learning program and offers insight into the impact of the use of technology on local library culture.
Learning organizations
- where people are continually learning how to learn together
- Goals, and the level they apply to, must be articulated
Professional development
- are we tapping people’s commitment and capacity to learn at all levels in an organization?
Library Technology Competencies
- are we gatekeeping who learns and who teaches library skills? (e.g. is information about metadata siloed in one department?)
When Carleton University Library migrated to a new LSP/LMS in 2020 they realized they were faced with past practices for staff training under justifiable scrutiny. They had a need for cross-departmental information sharing and learning. Many repeated questions which could be answered by vendor documentation and better communication between departments.
They made a LSP Experts Program:
- cross departmental membership
- members are supposed to share information with their departments
- content of program was in 5 steps, background about the system, skill building in various segments of the LSP software, understanding analytics of LSP, troubleshooting and support (internal and external documentation and ticketing workflows), continuous learning (each member of cohort commits to information sharing and keeping up to date)
- many synchronous presentations & discussion, some async readings. All presentations recorded and stored in the LMS.
- Periodic check-in meetings after cohort completion (What’s 1 new thing you’ve learned in past time_since_last_checkin?)
- Requires commitment from management and sense of ownership by staff
See work of Clare Thorpe for further examples applied to libraries.
https://doi.org/10.1108/LM-01-2021-0003
https://blogs.ifla.org/cpdwl/2021/12/17/what-they-said-clare-thorpe-webinar/
Q&A
Q. How did you determine need to know v. good to know?
A. She sent out a questionnaire ahead of time about what people wanted to know. She also, because she was seeing support tickets, had identified areas where people were having trouble with using the LSP software.
Learning From Your Knowledge Base
Robert Heaton
The “knowledge base” is an application of structured metadata principles that has revolutionized library resource management, allowing librarians to manage acquired items in packages rather than individually. The NISO recommended practice “Knowledge Bases and Related Tools,” or KBART, has been central to this shift since its release in 2010, ensuring that patrons can connect dependably and accurately to library-provided materials. Heaton explains ways librarians can expand the use of knowledge bases in local discovery and access systems, encourage content providers to adopt KBART when negotiating license agreements, and contribute to NISO’s maintenance of the recommended practice.
NISO recommended practice KBART. https://www.niso.org/standards-committees/kbart
Knowledge bases work at the package level. The company supplying the knowledge base keeps it up to date.
There is great opportunity for automation relying on APIs. Not every publisher has done this yet but it is picking up steam.
KBART is still developing. New content types and fields are becoming important and KBART intends to adjust to evolve with these in time.
What librarians can do:
- ask content providers to support it, get clauses in contracts
- if vendors already support KBART, ask them about automation
- look for other KBART applications, can work for things other than e-journals lists
- offer public comment on Phase III of KBART recommendations
Using Internal Communications to Create Collaboration: So Long Silos
Meghan Kowalski
Libraries often spend money and time marketing and communicating to their users and patrons. How much time do you spend communicating internally? Kowalski shares the benefits of internal communications in breaking down traditional silos to foster collaboration and create a more cohesive team. She discusses activities that support all forms of work: in-person, online, and hybrid. She demonstrates the value of communicating in all directions, be it to a team of reports or to management and administration.
Internal communications help staff see where they fit in the grand scheme of the organization.
Silos smother collaborations. The more staff know, through internal communication, the better ‘brand advocates’ they can be with your user base.
Benefits
- forces you to write things down, codifing them, building up knowledge within the organization
- shared updates bring everyone along towards projects on a similar timeline
- allows everyone to hear from everyone else
- good 2-way communication uncovers roadblocks and workflow problems
Types of internal communication
- administrative: updates, policies
- team-building: input / feedback / “What did you…”
- water cooler: fun, personal updates, content recommendations
- kudos: jobs well done
Meetings remain important, physicality is real and some ideas are much better explained verbally. Email is good for forcing things to be written and searchable. Chat (Slack/Teams/Other) useful for fun water cooler communication.
Own wins and losses. Owning wins is a no-brainer. Owning losses shows people that innovation and occasional failure are valued. Encourage critical reflection. Provide an opportunity for anonymous feedback.
Avoid spamming, make written communication clear and purposeful. Good idea to have a “no communication” day per week when everyone knows there will not be administrative (or other type) communication.
Q&A
Q. Recommended platforms?
A. Nothing in particular but be wary of having too many platforms. Communication is good but fatigue about which information is where is real. (E.g. having multiple chat locations is bad)
Q. Are there policies on what NOT to say in chats or water cooler platforms?
A. If your organization has an HR office those should be sufficient. General rule “Don’t say it if you aren’t willing to be fired for it.”
Increasing Faculty Engagement With Makerspace Technologies
Chris Woodall
Have you had trouble getting faculty to make use of the technology in your makerspace? Libraries often build spaces that offer all kinds of exciting technologies, but sometimes faculty do not make use of the equipment. Due to budgets that are already stretched thin, faculty do not always have the resources or expertise to try out new technologies in their courses. Woodall highlights how they turned this around when Salisbury University Libraries partnered with the campus’s Faculty Learning Communities (FLC) program to create an opportunity for faculty interested in technologies like 3D printing and AR/VR to share their knowledge and explore how these technologies can enhance their courses. Through this program, they were able to develop a core group of evangelists on campus who could spread the word about how these technologies can be helpful for teaching in a wide variety of disciplines. Faculty were much more engaged and willing to work with the makerspace.
At their institution they don’t have big engineering program and consequently did not have big engagement with makerspace via coursework. They require students to pay for their supplies but supplies are sold to students at-cost. This impacts number of students they can work with and some faculty are reluctant to require using makerspace because of added costs.
How could they increase usage?
- improve awareness via marketing
- relocated to a larger, more visible, space
- had goal of getting faculty to increase in-class learning activities. The faculty who did use the space were largely siloed.
Developed a Faculty Learning Community around the makerspace
- interdisciplinary
- at their university all FLCs must be approved and when approved get funding from Provost
- they have 18 faculty who are currently involved, perhaps even a little bit larger than ideal
- goal is simply to increase awareness of and usage of the makerspace
- individual FLC members give talks about how they’ve used the technology
- Provost’s Office funded a mini-grant to support faculty who were going to use makerspace tech in their courses
Review of projects funded by the mini-grant. Speculated that the model might work even without a financial incentive; could offer recognition in newsletters and promotional materials or perhaps course release.